Cap. 6 - Visualização de dados
6.1
Utilizando o banco de dados penguins compare o comprimento do bico entre as diferentes espécies de penguins. Utilize um gráfico de caixa (boxplot) para ilustrar a variação intraespecífica e possíveis outliers nos dados. Para melhorar o seu gráfico, lembre-se de nomear os dois eixos corretamente, definir um tema e posicionar a legenda.
Solução:
# Carregando pacotes necesários
library(tidyverse)
library(ecodados)
# Dados
penguins <- palmerpenguins::penguins
# Edição dos nomes das colunas para português
# names(penguins)
colnames(penguins) <- c("especies", "ilha", "comprimento_bico",
"profundidade_bico", "comprimento_nadadeira",
"massa_corporal", "sexo", "ano")
# Gráfico: Boxplot do tamanho do bico entre as diferentes espécies
ggplot(penguins, aes(y = comprimento_bico, x = especies, fill = especies)) +
geom_boxplot() +
theme_bw(base_size = 16) +
theme(
legend.position = "top"
) +
labs(fill = "Espécies",
x = "Espécies", y = "Comprimento do bico (mm)")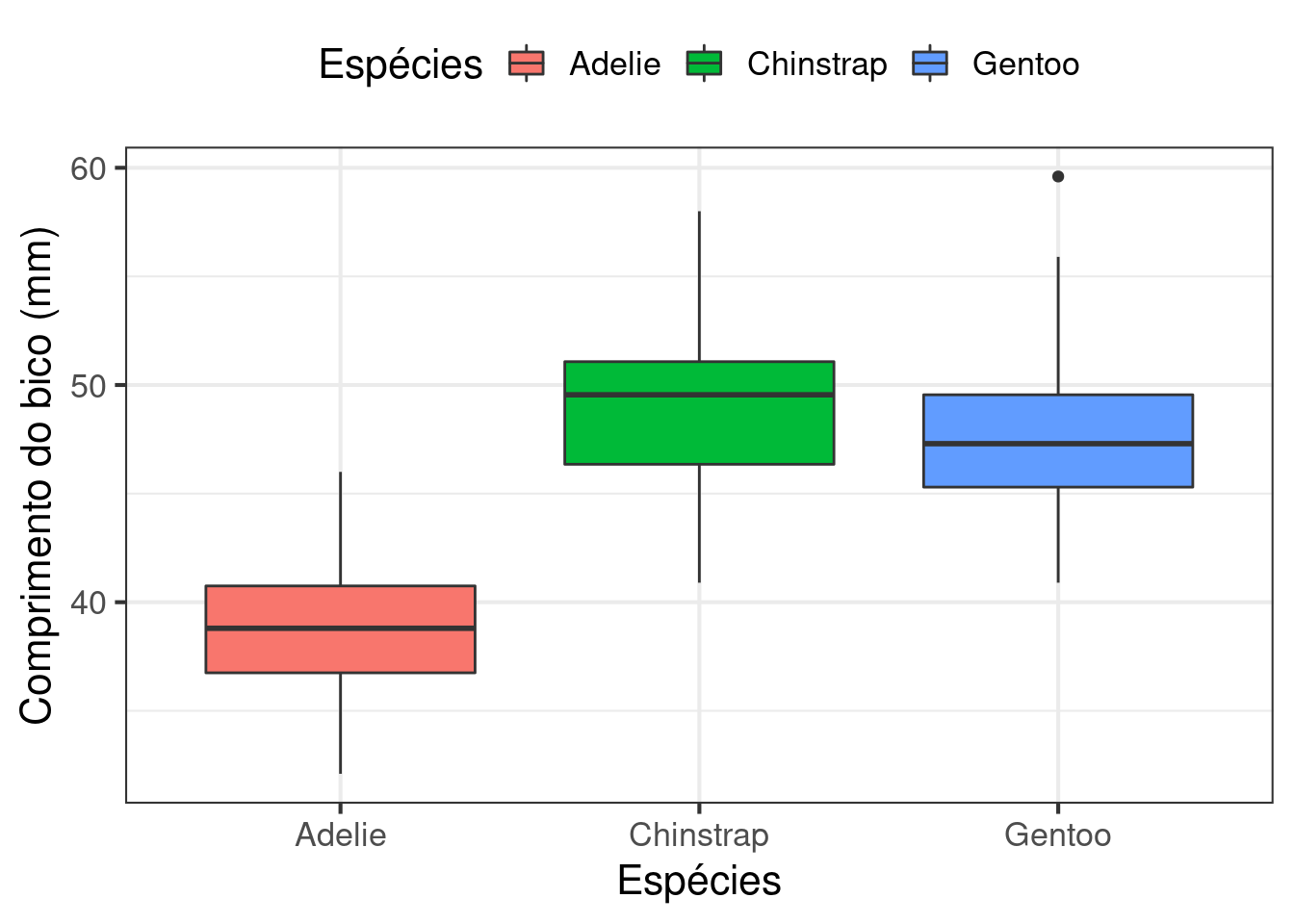
6.2
Utilizando o banco de dados penguins faça um histograma com a distribuição da massa corporal para cada uma das espécies. Utilize uma cor de preenchimento para cada espécie.
Solução:
ggplot(penguins, aes(x = massa_corporal, fill = especies)) +
geom_histogram(alpha = .5, position = position_dodge()) +
theme_bw(base_size = 16) +
labs(x = "Massa corporal (g)",
y = "Frequência",
fill = "Espécie")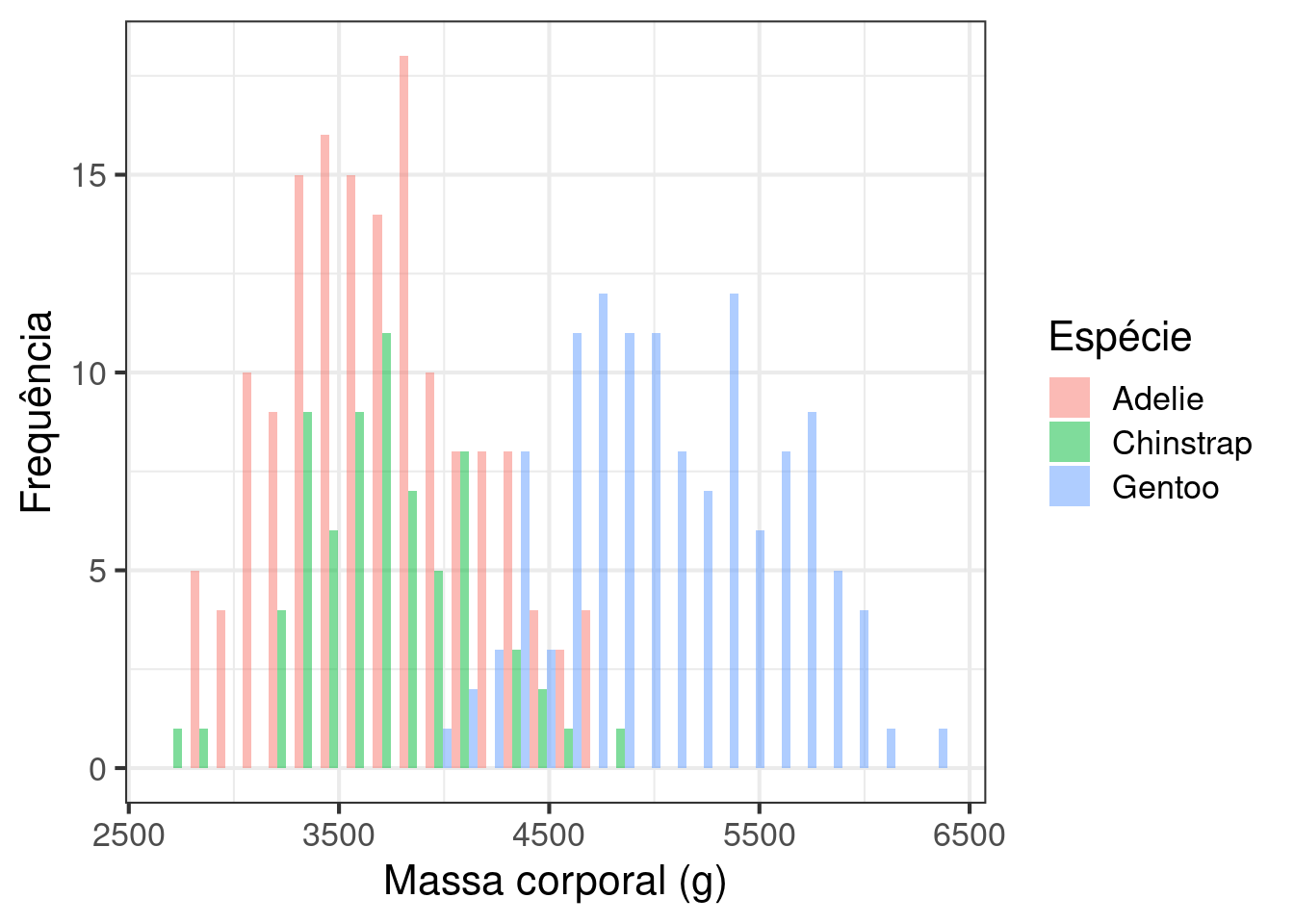
6.3
Utilizando o banco de dados penguins, faça três gráficos com o mesmo eixo Y e eixo X. Coloque o comprimento das nadadeiras no eixo Y e as espécies de pinguins no eixo X. No primeiro gráfico, utilize o geom_jitter() para plotar os dados brutos. No segundo gráfico, utilize o geom_violin() para mostrar a distribuição de densidade dos dados. No terceiro gráfico, utilize o geom_boxplot() para destacar a mediana e os quartis.
Solução:
# Gráfico de jitter com dados brutos
pjitter <- ggplot(penguins, aes(y = comprimento_nadadeira, x = especies )) +
geom_jitter()
pjitter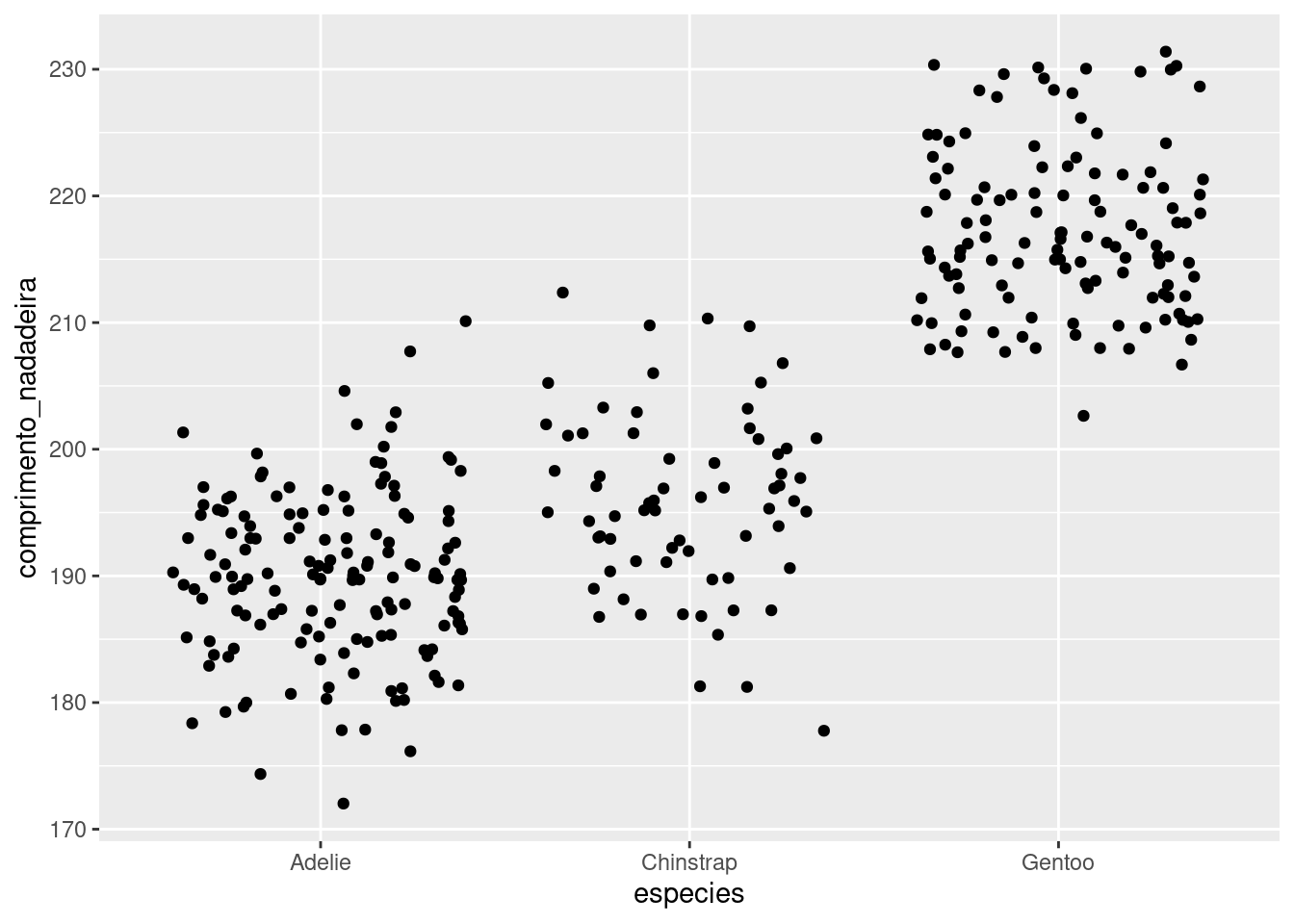
# Gráfico violin com a densidade dos dados
pviolin <- ggplot(penguins, aes(y = comprimento_nadadeira, x = especies )) +
geom_violin()
pviolin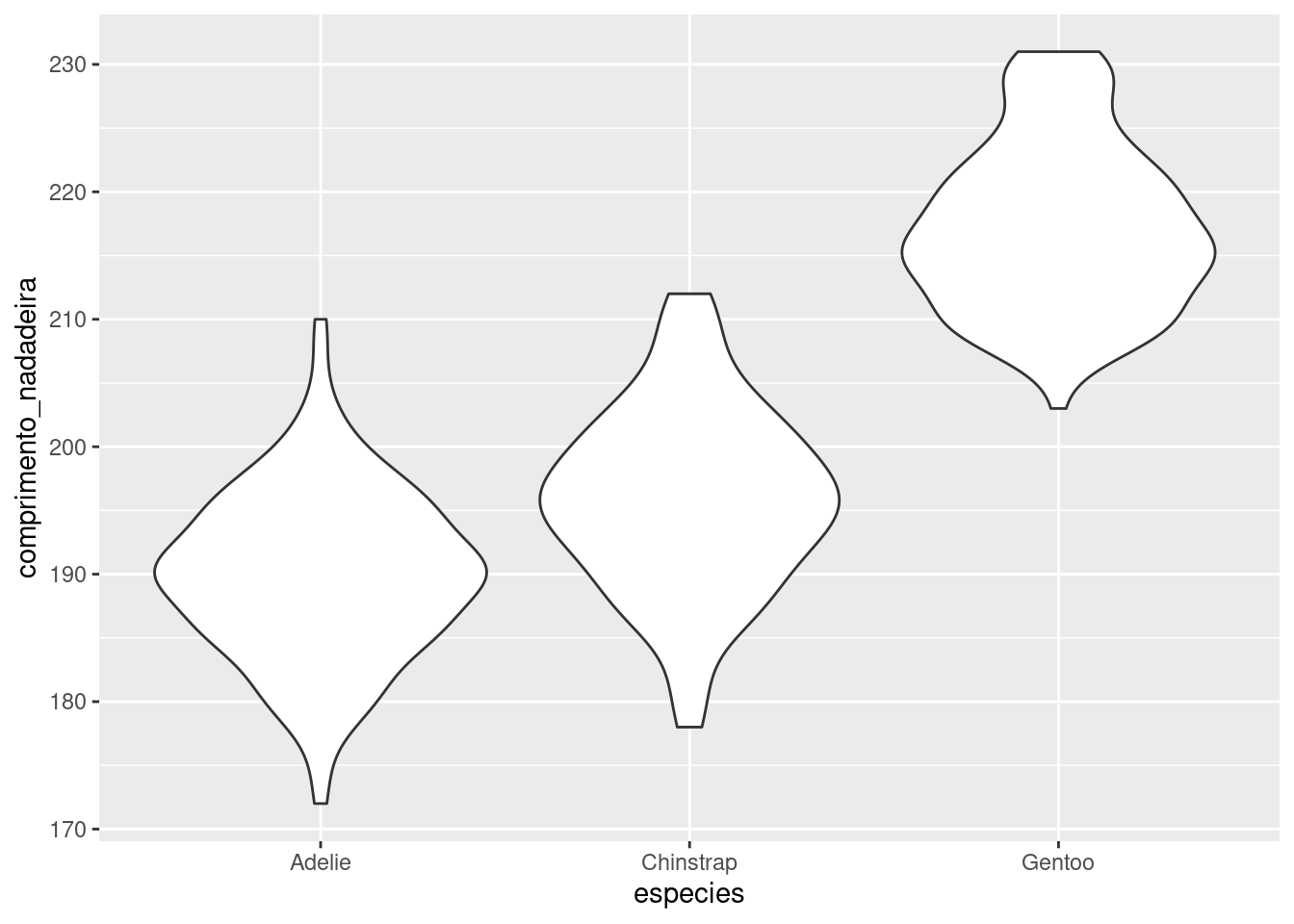
# Gráfico de caixa com a media e os quartis
pcaixa <- ggplot(penguins, aes(y = comprimento_nadadeira, x = especies )) +
geom_boxplot()
pcaixa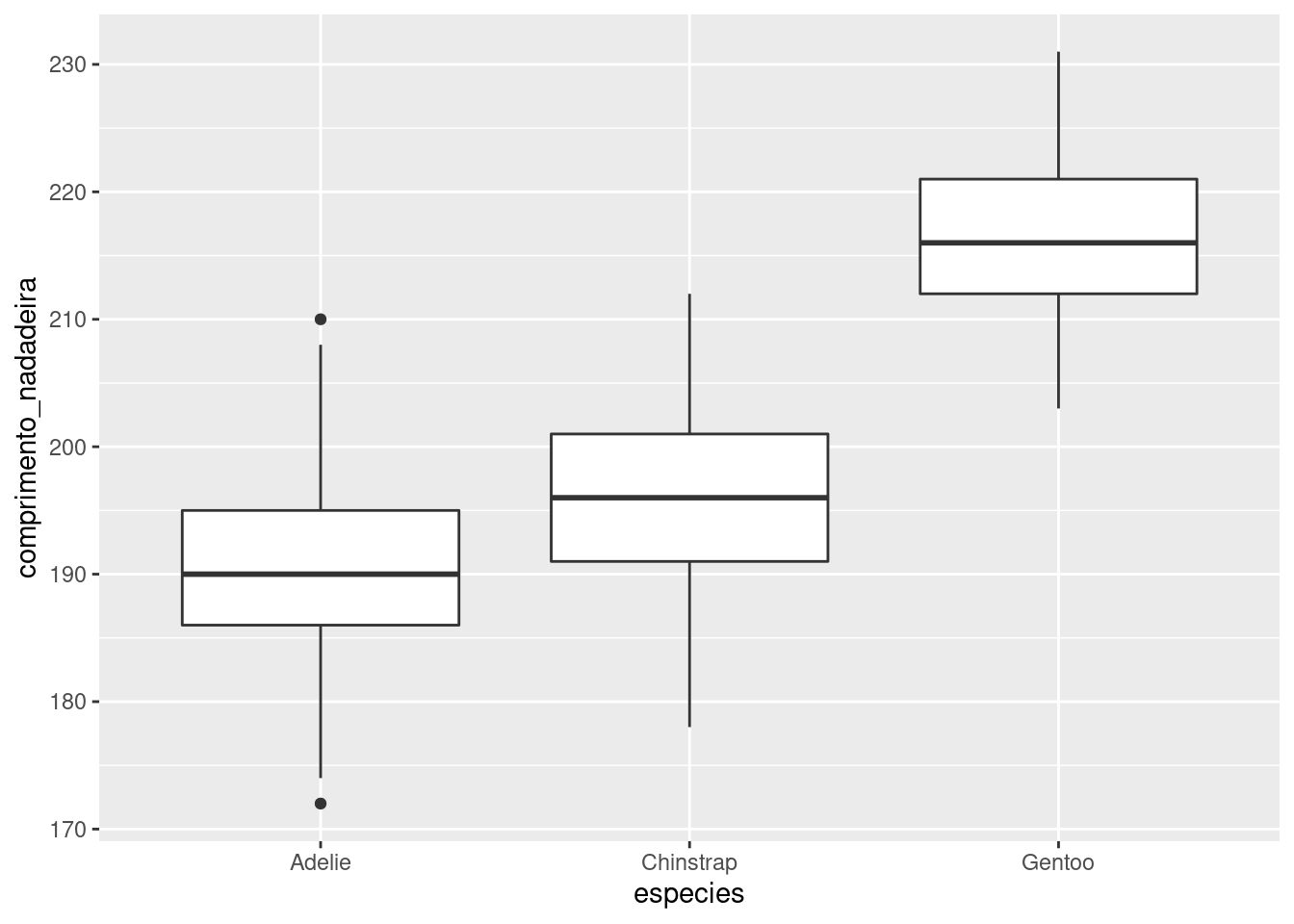
6.4
Se você conseguiu resolver o exercício 6.3, agora dê um passo a mais e compare os três gráficos lado a lado utilizando a função grid.arrange(). Lembre-se de colocar um título informativo em cada um dos gráficos antes de juntá-los em uma prancha única. Ao comparar os 3 tipos de gráficos, qual você considera mais informativo? Experimente combinar mais de um “geom” (camadas) e produzir gráficos ainda mais interessantes.
Solução:
# colocando um título em cada gráfico
pjitter <- pjitter + labs(title = "Plot com jitter")
pviolin <- pviolin + labs(title = "Plot com violin")
pcaixa <- pcaixa + labs(title = "Plot com boxplot")
# juntando os 3 gráficos em um só
# Carregando o pacote gridExtra
library(gridExtra)
grid.arrange(pjitter, pviolin, pcaixa, ncol = 3)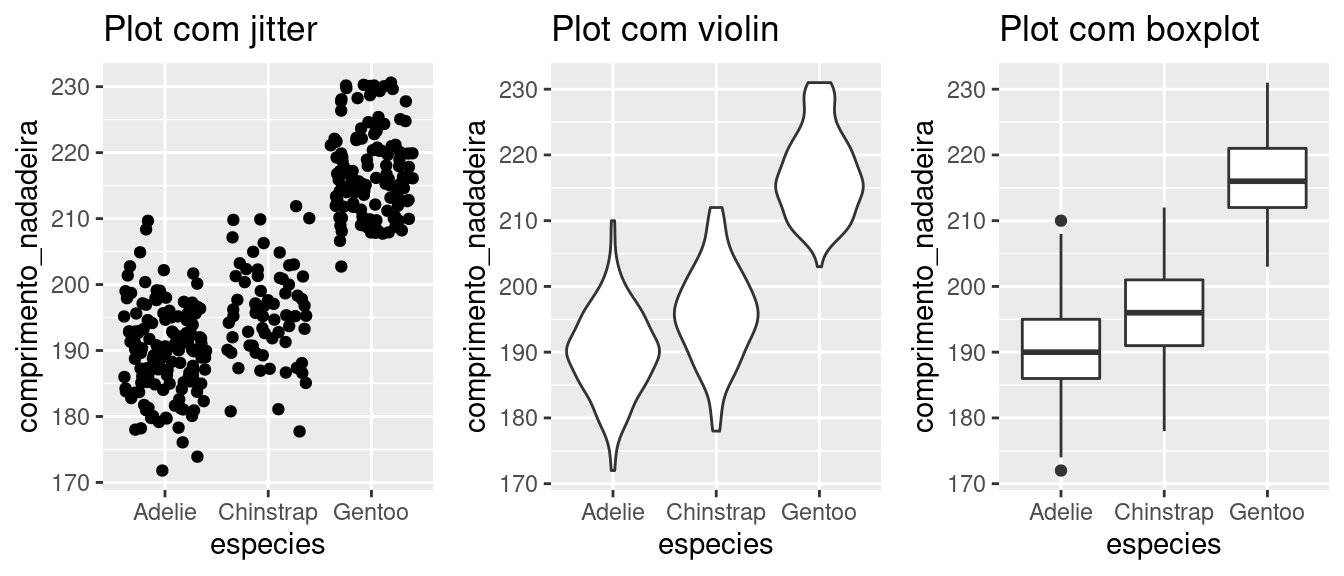
Agora misturando as camadas.
# Misturando geoms
ggplot(penguins, aes(y = comprimento_nadadeira, x = especies )) +
geom_jitter(size = .5, width = .2, aes(color = especies)) +
geom_boxplot(aes(fill = especies), alpha = .2, width = .2) +
geom_violin(fill = "gray", alpha = .1) +
theme_classic(base_size = 16) +
theme(legend.position = "none") +
labs(y = "Comprimento da nadadeira (mm)",
x = "Espécie de pinguim")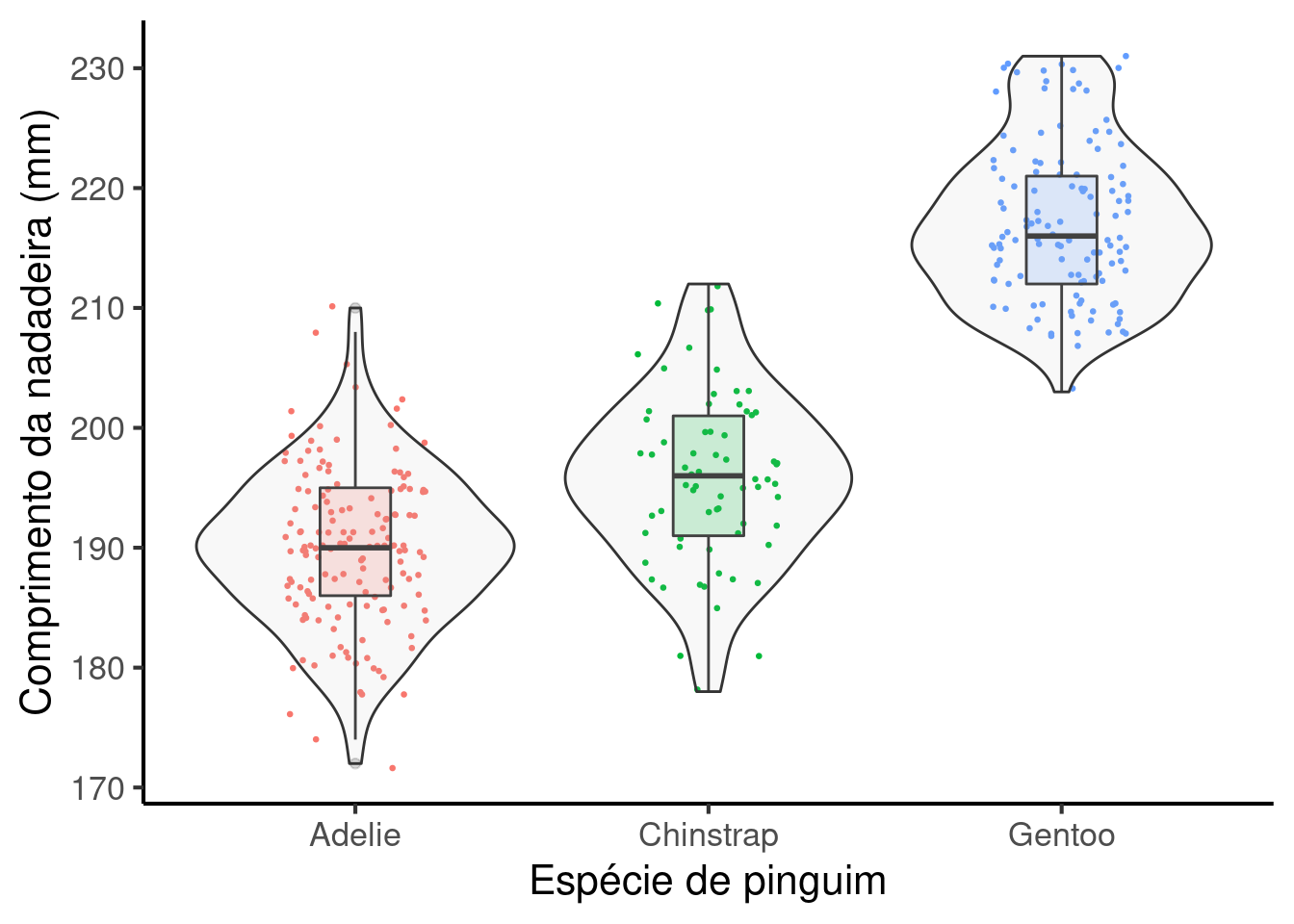
6.5
Utilize o banco de dados ecodados::anova_dois_fatores para construir um gráfico de barras com a média e o erro padrão do Tempo (Tempo para eliminar a droga do corpo) no eixo Y em função da variável Pessoas (XX, ou XY) e Idade (jovem ou idoso). Antes de fazer o gráfico leia com atenção a descrição do mesmo através do comando ?ecodados::anova_dois_fatores. Uma dica, utilize fill dentro do aes para representar um dos fatores (ex. Pessoas). O outro fator você pode representar no eixo X. Veja se consegue, se não conseguir pode olhar a cola com a solução para aprender como é feito. Outra dica, pesquise sobre a função stat_summary() ela irá te ajudar a calcular a média e o erro padrão dentro do comando que gera o gráfico.
Solução:
# entenda o banco de dados primeiro
?ecodados::anova_dois_fatoresVersão 1: calculando a média e o erro padrão dentro do próprio gráfico.
ggplot(anova_dois_fatores, aes(y = Tempo, x = Idade, fill = Pessoas)) +
geom_point(position = position_dodge(width = .9), size = .5) +
stat_summary(fun = mean, geom = "bar", position = position_dodge(width = .9), alpha = .75) +
stat_summary(fun.data = mean_se, geom = "errorbar", position = position_dodge(width = .9),
width = .2) +
scale_fill_manual(values = c("steelblue", "orange")) +
theme_bw(base_size = 16) +
labs(y = "Tempo (dias após administração)",
x = "Grupo etário")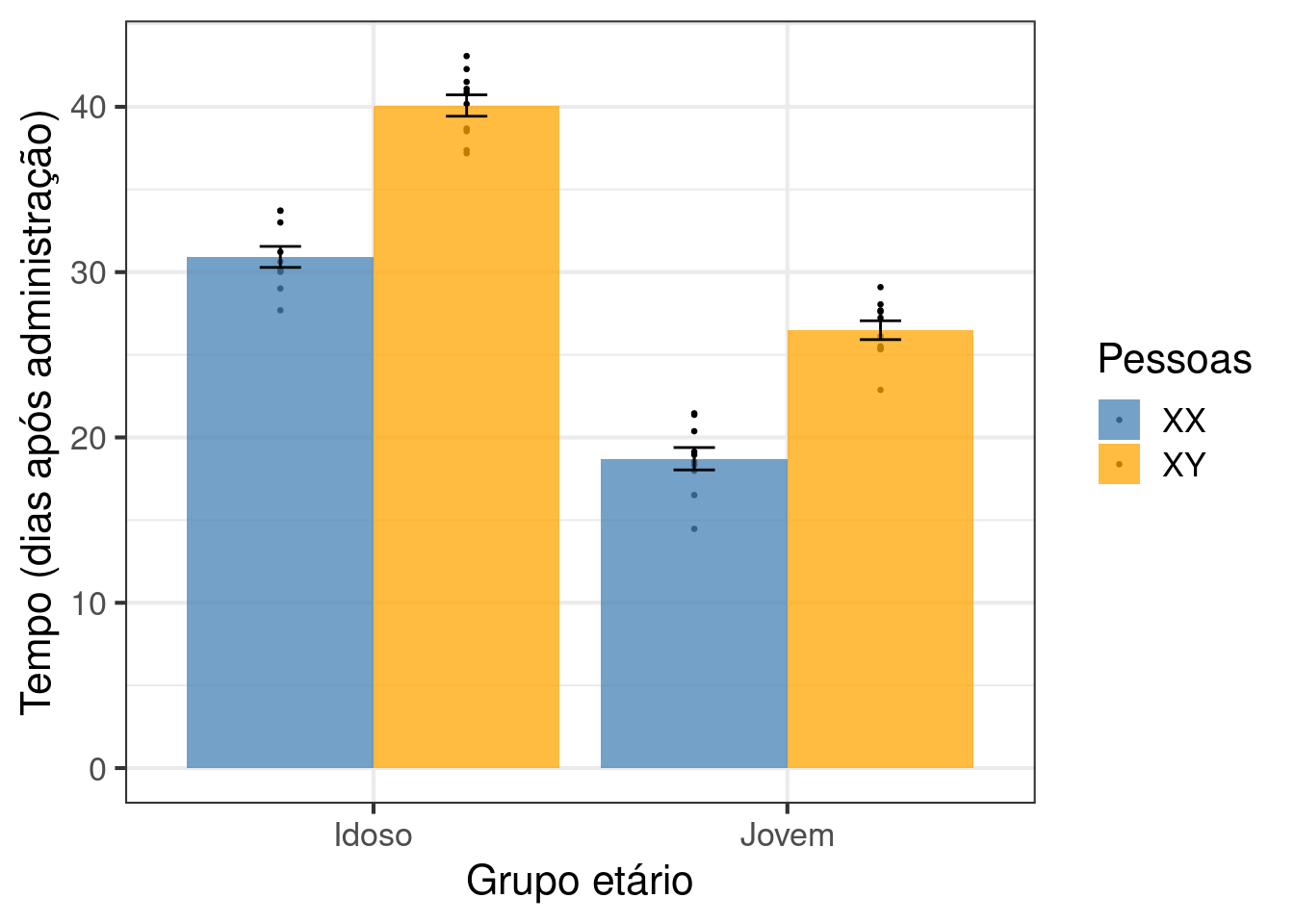
Versão 2: calculando a média e o erro padrão antes de produzir o gráfico.
# Calcular o desvio padrão
anova_media <- anova_dois_fatores %>%
dplyr::group_by(Idade, Pessoas ) %>%
dplyr::summarise(media = mean(Tempo, na.rm = TRUE),
desvio = sd(Tempo, na.rm = TRUE))
#Veja como ficou
head(anova_media)
#> # A tibble: 4 × 4
#> # Groups: Idade [2]
#> Idade Pessoas media desvio
#> <chr> <chr> <dbl> <dbl>
#> 1 Idoso XX 30.9 2.01
#> 2 Idoso XY 40.1 2.04
#> 3 Jovem XX 18.7 2.14
#> 4 Jovem XY 26.5 1.80Agora use esse banco de dados para plotar a média e o erro padrão.
# Gráfico de barras com desvio padrão
ggplot(data = anova_media, aes(y = media, x = Idade, fill = Pessoas)) +
geom_bar(stat = "identity", alpha = .75, position = position_dodge()) +
geom_errorbar(aes(ymin = media - desvio, ymax = media + desvio),
width = .1, position = position_dodge(width = .9)) +
scale_fill_manual(values = c("steelblue", "orange")) +
theme_bw(base_size = 16) +
labs(y = "Tempo (dias após administração)",
x = "Grupo etário")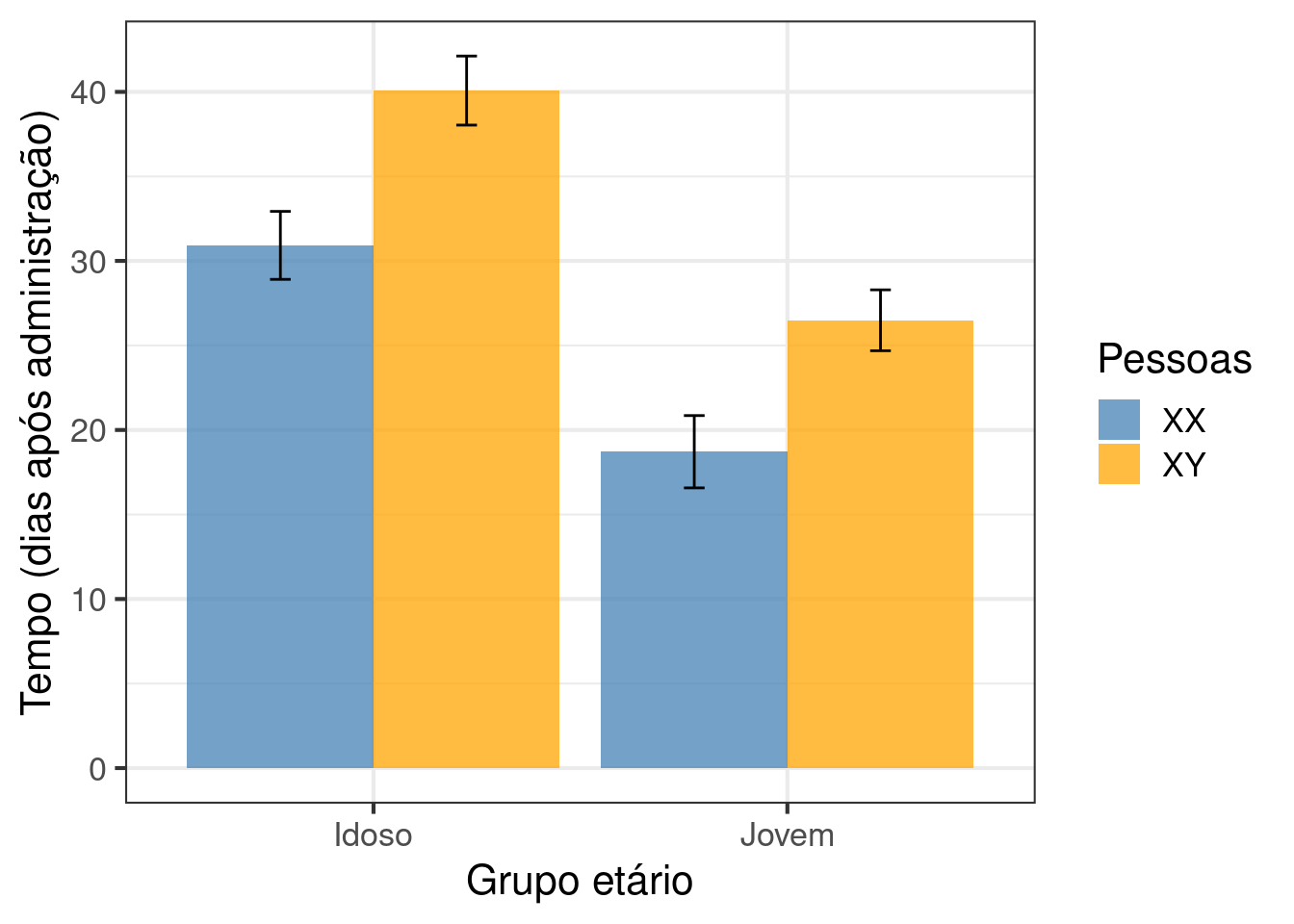
6.6
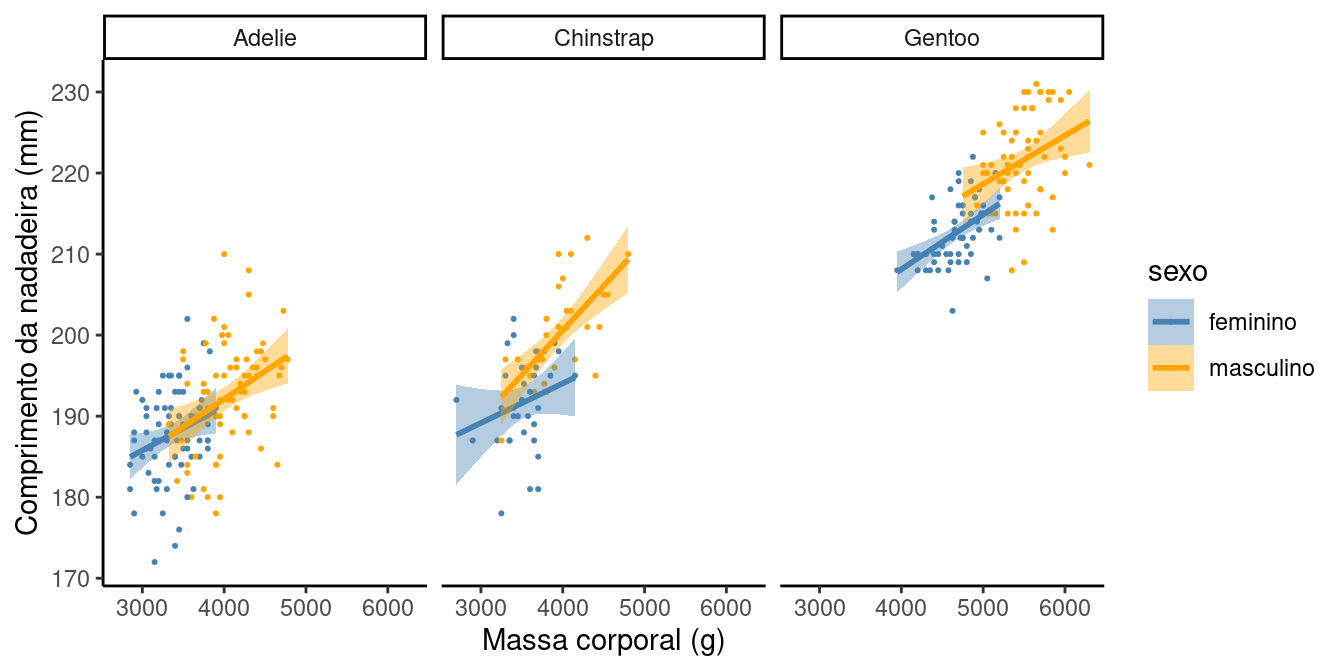
Utilize o banco de dados penguins para criar um gráfico de dispersão entre o tamanho da nadadeira (eixo Y) e a massa corporal (eixo X). Utilize o argumento fill para ilustrar com cores as diferenças entre os sexos e utilize a função facte_grid() para criar um gráfico separado para cada espécie de pinguim. Se você não conhece essa função, dê uma olhada no help ?facet_grid. Você também pode utilizar a função drop_na() para excluir os dados faltantes da coluna sexo.
Solução:
# primeiro vamos traduizir a coluna sexo para o português
penguins$sexo <- fct_recode(penguins$sexo, masculino = "male", feminino = "female")
ggplot(penguins %>% drop_na(sexo), aes(y = comprimento_nadadeira, x = massa_corporal,
color = sexo, fill = sexo)) +
geom_point(size = .4) +
geom_smooth(method = lm) +
facet_grid(~especies) +
scale_color_manual(values = c("steelblue", "orange"), aesthetics = c("fill", "color")) +
theme_classic() +
labs(
y = "Comprimento da nadadeira (mm)",
x = "Massa corporal (g)"
)